
OpenAI’s new AI platform Point-E can generate 3D models from text prompts
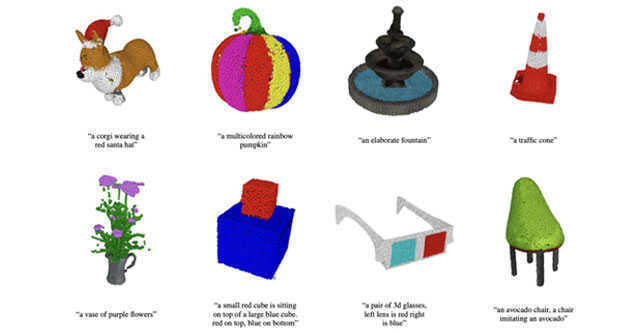
After fascinating Internet users with Dall-E and ChatGPT, AI research firm OpenAI has released another generative AI platform, Point-E, which can generate “diverse and complex” 3D models from text input and images conditioned on it.
OpenAI claims that Point-E can generate 3D models in “only 1-2 minutes” on a single Nvidia GPU (graphics processing unit) in comparison to existing generative image models.
Point E uses a text-to-image diffusion model to first generate a single synthetic image and then uses another diffusion model to produce a 3D point cloud from the image generated by the first model. Both these steps take a few seconds and do not require optimization procedures. Point clouds are discrete sets of data points representing a 3D shape. Diffusion models are generative models used to generate data similar to what they have been trained on.
OpneAI’s Dall-E 2, which can generate images and artwork from text instructions, also uses a text-to-image generation model. Both use OpenAI's natural language generation (NLG) model GPT3 which uses deep learning to create human-like text.
According to OpenAI, the text-to-image model has been trained on a large database of text and image pairs. It can handle diverse and complex prompts. On the other hand, the image-to-3D model has been trained on a smaller dataset of images and 3D models. OpenAI said that it has trained the model on several million 3D objects and metadata associated with it.
Further, OpenAI also explains why Point E stands out from other text to 3D generative models. For instance, models that use pre-trained text-to-image models to optimize 3D representations require expensive optimization processes, which in turn require more computing power and time. Similarly, models which train on the paired text and 3D data are difficult to scale due to the lack of large data sets.
Instead of directly generating point clouds based on text, OpenAI breaks the process into three steps. In the first step, a synthetic image is created from text input. In the second step, a coarse point cloud based on the synthetic image is generated. In the third step, a fine point cloud based on the low-resolution point cloud and the synthetic image is generated.
That said, Point-E has its limitations. Researchers at OpenAI acknowledged that the model suffers from issues such as bias inherited from the dataset it has been trained on just like the Dall-E 2 system. They also warned about the risk of it being misused for creating blueprints of dangerous objects, which can then be converted into actual objects using 3D printers.
Next Article